#브라이틱스스튜디오 #브라이틱스서포터즈 #BrighticsAI #데이터분석 #연관성분석

쇼핑을 하다보면 옆 추천 상품 리스트가
내가 딱 원하던, 필요하다고 느꼈던 상품인 적 있으셨나요?
같은 분야의 상품이 아닌데도요!
이런 것들은
소비자의 구매 패턴을 분석해서,
이러이러한 상품을 구매한 사람들은
이러이러한 상품에도 관심을 갖는 경향이 있다!
라는 결론을 바탕으로 한 것일 수 있어요.
이런 분석을 연관성 분석, 또는 장바구니 분석이라고 합니다!
이번에는 브라이틱스AI 연관성 분석 튜토리얼을 바탕으로
실제 연관성 분석 실습을 진행해보았어요.
𝒃𝒓𝒊𝒈𝒉𝒕𝒊𝒄𝒔 𝒑𝒓𝒐𝒄𝒆𝒔𝒔

해당 포스트는 PC 화면에 최적화되어 있습니닷 'ㅅ'!
𝟏. 𝐋𝐨𝐚𝐝 𝐃𝐚𝐭𝐚

먼저 분석하고자 하는 데이터를 Load 함수로 불러와줍니다!
이번 실습에서 불러온 데이터는
- cust_id : 고객 ID
- ctg_1 : 상품 대분류
- ctg_2 : 상품 소분류
항목을 가진 85,309개의 구매 데이터입니다!
여기서 같은 고객 ID가 여러 행이라면 한 고객이 여러 상품을 구한 것으로 볼 수 있겠죠?
이렇게 한 고객이 어떤 상품을 함께 구매했는지를 분석해서 상품 구매 패턴을 인식한다면,
이 구매 패턴을 바탕으로 A를 구매한 고객에게 적절한 B 상품을 추천해줄 수 있을 거예요.
이런 분석을 연관성 분석(Association Analysis)이라고 하는데,
위와 같이 상품 구매의 연관 형태를 분석하는 식이라 장바구니 분석(Market Basket Analysis)이라고도 부른답니다!
𝟐. 𝐏𝐫𝐞-𝐩𝐫𝐨𝐜𝐞𝐬𝐬𝐢𝐧𝐠
그럼 연관성 분석 함수를 가져오기 이전에, 우리가 원하는 형태로 데이터를 다듬어주는 전처리 과정이 필요하겠죠?
이번 실습의 전처리 과정은 다음과 같아요.
① 한 명의 고객이 같은 상품을 두 번 중복하여 구매한 경우, 모두 하나만 남기고 지워줍니다.
② 여러 상품 간 구매 패턴을 인식해야 하니, 한 상품만 구매한 고객도 모두 지워줍니다.

그럼 ①번 중복 구매 데이터 삭제부터 시작해볼까요? 이번 실습에서 처음 나오는 함수인 것 같아요!
Distinct 함수는 선택한 항목들이 중복되는 데이터를 하나만 남기고 삭제해주는 함수입니다.
고객 데이터와 상품 소분류를 선택해주어서 함수를 실행해봤어요.
(소분류가 같다면 당연히 대분류도 동일할테니 두 항목만 선택해주었습니다!)
이 데이터는 중복 구매 데이터가 없었는지 행 수는 그대로이긴 하지만! ٩(●'▿'●)۶
분석의 정확도를 높이기 위해서 한 번 체크해주어야 할 부분이겠죠?
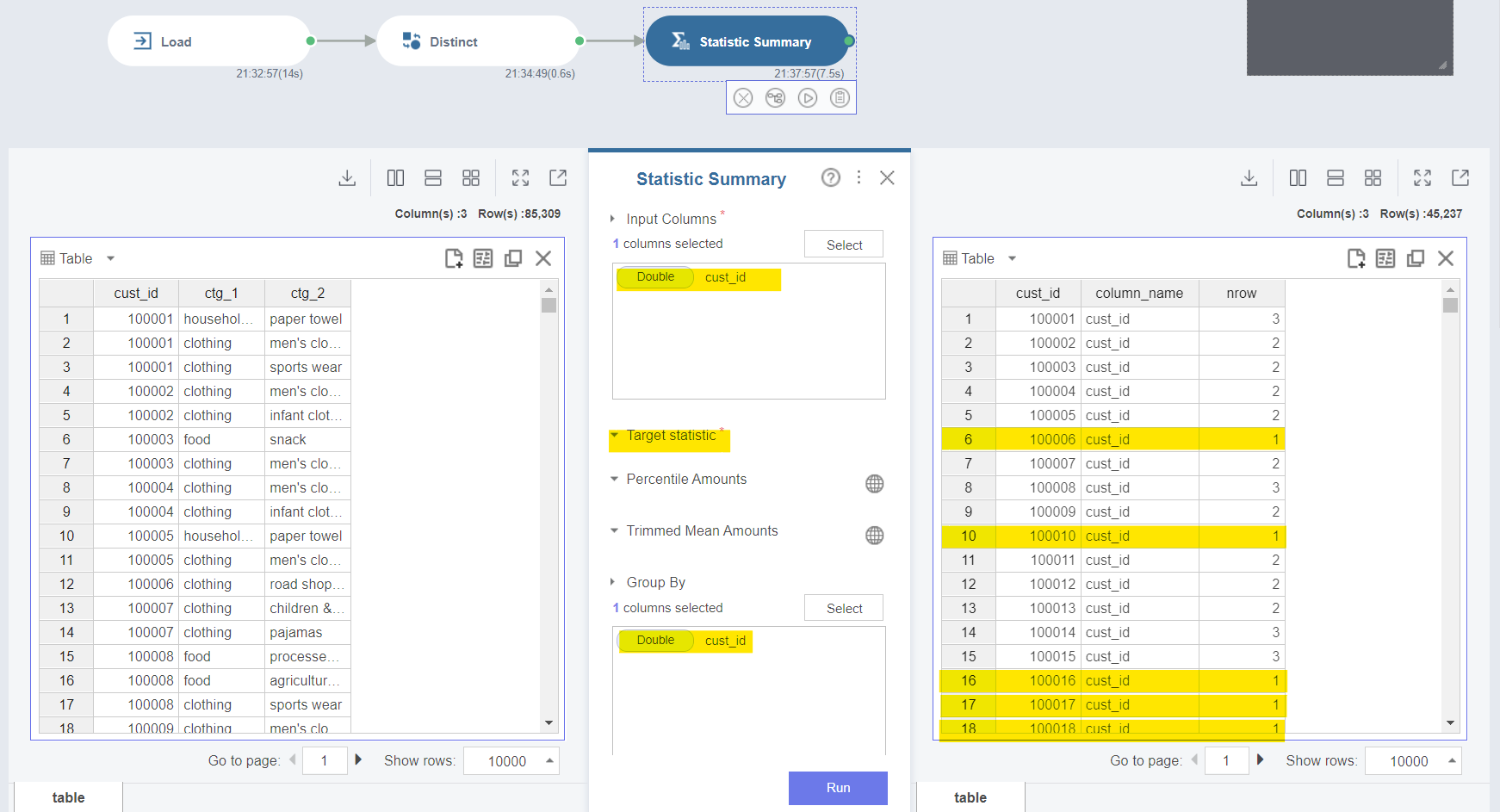
그리고 ②번 한 항목만 구매한 데이터를 삭제해줘볼게요! 이 전처리는
- 한 상품만 구매한 고객 확인하기 (cust_id 각각이 포함된 횟수가 1이라면 한 번만 구매한 것이겠죠?)
- 두 번 이상 구매한 고객의 cust_id만 추출하기
- 해당 cust_id가 들어간 데이터만 정리하기
단계로 이루어집니다.
위 화면은 그 중에서 Statistic Summary 를 활용해서 cust_id 각각을 센 횟수를 확인한 결과입니다!
Target Statistic을 Number of row, Group By cust_id 로 설정하면 cust_id 별 나온 횟수가 나와용


그리고 Filter 함수 소환! Filter 함수는 조건을 설정하면 그 조건에 부합하는 데이터만 뽑아주는 함수였죠?
Statistic Summary 함수와 연결하여, nrow 가 1을 초과하는 데이터만 뽑아주었어요.

그리고 이 Filter 함수의 결과와 Statistic Summary 이전 Distinct 함수 결과를 둘 다 Join 으로 연결해주면?
Filter 함수와 Distinct 함수 결과 각각의 데이터 내 cust_id로 교집합을 만족하는 데이터,
즉 nrow 가 1을 초과하는 데이터만 결과적으로 뽑아낼 수 있게 됩니다.
𝟑. 𝐀𝐬𝐬𝐨𝐜𝐢𝐚𝐭𝐢𝐨𝐧 𝐑𝐮𝐥𝐞 & 𝐕𝐢𝐬𝐮𝐚𝐥𝐢𝐳𝐚𝐭𝐢𝐨𝐧

전처리 과정도 끝났으니 본격적인 연관성 분석! 이지만 사실 Association Rule 함수면 한 방에 끝이 나요.
User Column은 cust_id이겠고, Item Column은 ctg_2를 선택해주면 되겠죠?
Min Support 와 Min Confidence는 각각 최소 지지도와 신뢰도를 입력할 수 있는 칸인데,
각각 0.005를 입력해준 후 실행해주었어요.
연관성 분석에서는 지지도, 신뢰도, 향상도 세 요소로
만들어낸 규칙이 얼마나 의미있는지 평가할 수 있는데요! (ADsP에서 들어본 바가 있음 .. ㅎㅎ)
연관성 분석 개념을 조금 더 공부하고 싶으신 분은 개인적으로 아래 영상을 추천드립니당

표로는 단번에 이해하기 어려우니 Association Rule Visualization 함수로 한 방에 시각화까지 끝내줍시당!

각 노드의 색상과 크기는 지지도(support), 연결선 색상은 향상도(lift),
연결선 두께는 신뢰도(confidence)를 반영한다고 쓰여져있어요.
간단히 이야기하자면, A를 구매했을 때 B를 구매한다! 라는 규칙에 있어서
지지도가 높으면 전체 거래 중에서 A, B 구매 항목의 빈도가 높다는 의미,
(연관성이 높아도 발생한 거래 내역이 거의 없다면 의미가 크지 않을 수도 있겠죠?)
신뢰도가 높으면 A 항목을 포함하는 거래 중에서 A, B 구매 항목의 빈도가 높다는 의미입니다.
그리고 향상도의 경우 값이 1인 경우 우연에 의한 관계라고 해석해요.
1보다 클 수록 우연이 아닌 규칙이라고 볼 수 있어요.
이러한 개념을 바탕으로 시각화 내용을 몇가지 살펴보자면,
가장 먼저 눈에 띄는 cookie 와 beverage 간의 관계!
비록 지지도가 높은 편은 아니지만,
cookie 를 구매하는 경우에 아주 높은 비율로 beverage를 구매하니
쿠키 옆 추천 상품으로는 다양한 음료 리스트를 두는 것이 좋을 것 같아요 !(•̀ᴗ•́)و ̑̑
그리고 지지도가 높은 남성/여성 의류 항목과 주변 요소와의 관계도 눈에 띄네요.
이외에도 하나하나 뜯어볼 수록 다양한 요소가 보여요!
여기까지 연관성 분석 실습에 대한 리뷰였습니다!
이렇게 하나하나 분석 전체를 직접 실습할 때마다
눈으로 읽을 때는 몰랐던 새로운 것들을 많이 알아가게 돼요.
데이터 분석에 관심이 있는 분이라면!
코딩을 아직 해본 적 없으시더라도 어렵지 않으니 한 번 시도해보세요!
읽어주셔서 감사합니다.
'𝟐𝟎𝟐𝟎 𝐛𝐫𝐢𝐠𝐡𝐭𝐢𝐜𝐬' 카테고리의 다른 글
| 브라이틱스 with 3rightics ♩。*✡ UCC 제작기 (0) | 2020.08.31 |
|---|---|
| 브라이틱스 서포터즈 UCC 팀미션 기획 후기 ˚✩☁︎︎⋆。 (0) | 2020.08.25 |
| 그래프로 보는 서울시 코로나19 확진자 현황 (08.11 00시 기준) - 브라이틱스 스튜디오로 살펴본 코로나19 확진자 데이터 (2) (0) | 2020.08.12 |
| 매장 판매량, 어떻게 높이지? - [Brightics Studio 실습] 차원 축소 - 주성분분석(PCA) (0) | 2020.08.11 |
| 설문조사 과제? 간단하게 퀄리티 있는 레포트 완성하기 ② - [Brightics Studio 실습] EDA (5) : 데이터 시각화 + Report (0) | 2020.08.11 |



